
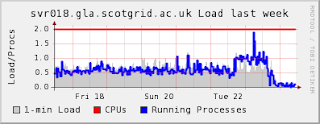
I'd noticed that over the last month the load on our DPM headnode had been higher than before we switched on
MonAMI checking of the DPM. Of course I instantly blamed the developer of said product. However, I disabled monami to prove that the load went down and lo... no change. Hmm.
I then started working out how to optimise the MySQL memory usage - we have about a 1.8G ascii file when I do a mysqldump -A and yet the innodb file takes up a whopping 4.4G on disk with tiny constantly rolling transaction logs of 5M.
As paul was here at cern (it's the
WLCG Workshop this week) we got together to hammer out some changes to our implementation. When we logged onto svr018 (The DPM Headnode) I noticed that monami was running again. Turns out that cfengine was "helpfully" restarting the process for us. Grr.
So, an evening of infrastructure management changes:
- we had i386 monami rpms installed - we'd hard coded the repo path rather than using the $basearch variable in our local mirror.
- we had to ensure that we had
backup=false in cfengine - where we had a config_dir directive (such as /etc/monami.d and /etc/nrpe.d) the applications were often trying to use someconfigfile.cfg and someconfigfile.cfg.cfsaved - ditto cron.d etc etc.
- we were sometimes trying to run 64 bit binaries on 32 bit architectures as we'd copied them straight from cfagent (normally nrpe monitors) - We've now using $(ostype) in cfagent which expands to linux_x86_64 and linux_i686 on our machines. Although cfengine sets a hard class of 32_bit and 64_bit but you can't use that in a variable.
- we now have the 'core' nrpe monitors (disk space, load, some process checks) installed on ALL servers not just the workernodes. Ahem. Thought we'd implemented that before.
- we've upgraded to the latest CVS rpm of monami on some nodes and we've got grooovy mysql monitoring. - oh and the load's gone down too.





