More Edinburgh storage-related news: One of our disks died during the night. Similar to the problem of failing SAM tests (see below) this happened during the Edinburgh<->Durham simultaneous read/write transfer test. It appears this has been quite a stressful operation for our site, although it should be noted that we lost power to the ScotGRID machines this week when the computing facility went down for maintenance. Unfortunately this happened a day earlier than we had originally been told. You can draw your own conclusions about that one.
The client tools for analysing the RAID setup confirm that a disk has broken, but also show that even though we have hot spares available to replace it, none of them have been used. The software is also highlighting a couple of other problems. Looks like some manual intervention is required.
Friday, September 29, 2006
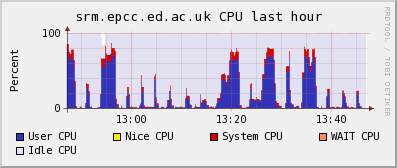
Problems, problems and more RM'ing problems. As of yesterday, we were still failing the ops lcg-rm SAM tests with the same issue as before (timing out of the 3rd party copy to the remote SE). The ops SAM SRM tests were all passing, as were the dteam SAM SRM and CE tests. However, yesterday afternoon things got worse and we started failing all SRM tests (dteam, ops) and all lcg-rm tests (dteam, ops). This appears to have been correlated with the start of the simultaneous Edinburgh<->Durham transfer tests which ran until ~0800 this morning. Even after the transfers stopped, the SAM tests continued to fail. Note, the dCache was still operational during this time.
This afternoon I started up the Edinburgh->Cambridge transfers. Initially everything was OK, but then I noticed a strange load pattern on the dCache head node which was causing the transfer rate to drop down to 0 for periods of ~10mins. Digging around, it appeared that the high load was due to the dcache-pool process on the head node (I had set up a small pool on the head node a few weeks ago). After shutting this down, then back on again, then off again, the relationship was confirmed. See the attached ganglia plot. The pool has now been switched off permanently. This is a warning to anyone attempting to run dCache with a pool on the SRM/PNFS head node. Presumably the high load generated by simultaneous reads and writes had started to cause the SAM failures. I am still waiting for further SAM tests to run, but hopefully this will return or state to how it was prior to the Durham test (i.e. just failing ops lcg-rm).
In an attempt to solve the ops lcg-rm problem I have stripped the dCache pool configuration back to basics. Again, I'm waiting on SAM tests to run before I can find out if this has been successful. Watch this space...
Thursday, September 21, 2006
As hinted at in previous posts I have created a kickstart build environment within CVOS. So as not to upset the CVOS tools this pretends to be another CVOS category and slave image called "alt". However, it boots pxe installer images and passes the magic kickstart file "autokick.php" to the installer kernel.
Different classes for each machine are supported, as well as the copying of skeleton files, etc.
The intention here is not to run a fully fledged installation from kickstart, but rather to get a base from which to then work.
From those around GridPP to whom I've spoken it seems that most people don't try to do to much within a kickstart environment, but instead ensure a ssh root login from the installer to finish the install after the machine has rebooted.
I'm now not thinking to bother with using CVOS for the grid nodes - at least not initially. It seems there's too much pain for no real gain in this. Single nodes are on their own and might as well remain there.
Different classes for each machine are supported, as well as the copying of skeleton files, etc.
The intention here is not to run a fully fledged installation from kickstart, but rather to get a base from which to then work.
From those around GridPP to whom I've spoken it seems that most people don't try to do to much within a kickstart environment, but instead ensure a ssh root login from the installer to finish the install after the machine has rebooted.
I'm now not thinking to bother with using CVOS for the grid nodes - at least not initially. It seems there's too much pain for no real gain in this. Single nodes are on their own and might as well remain there.

Rain stopped play today on the cluster.
The weather was so horrible I stayed at home. Unfortunately this coencided with my PXE boot environment breaking, so that no machine would install itself. As IPMI is not working I couldn't find out why, despite putting some debugging traces into the kickstart file. I suspect the disk formatting might be going wrong - building RAID partitions in kickstart has always seemed flaky.
Wednesday, September 20, 2006
Some notes on switching to the OPS VO for reporting.
I found that Glasgow's WNs were missing an default SE entry for the OPS VO, which caused us to be basically down for the whole week. That was easy to fix.
However, more puzzling, Glasgow and Durham's LFCs are also failing, for no good reason that I can see. Glasgow's certainly has a valid host certificate and the permissions on the catalog seem to be ok. As I'm so pressed for time with the new cluster being our most urgent priority I have just removed our LFC from the site BDII. This should stop SAM from trying to test this element of the site. The catalog is unused, of course, as ALICE are the only LCG VO who require a site local catalog, and they have a very different notion of what a T2 should provide so they never send us any jobs.
Perhaps Durham should do the same, until the problem is better understood?
One really annoying thing about the SAM tests is that as there are so many more tests there's no nice single page summary which shows the site's status. And selecting the individual tests is quite awkward in the way it's rendered in safari at any rate.
I will change my magic safari scotgrid status tab to show at least the SE and CE tests for the sites.
I found that Glasgow's WNs were missing an default SE entry for the OPS VO, which caused us to be basically down for the whole week. That was easy to fix.
However, more puzzling, Glasgow and Durham's LFCs are also failing, for no good reason that I can see. Glasgow's certainly has a valid host certificate and the permissions on the catalog seem to be ok. As I'm so pressed for time with the new cluster being our most urgent priority I have just removed our LFC from the site BDII. This should stop SAM from trying to test this element of the site. The catalog is unused, of course, as ALICE are the only LCG VO who require a site local catalog, and they have a very different notion of what a T2 should provide so they never send us any jobs.
Perhaps Durham should do the same, until the problem is better understood?
One really annoying thing about the SAM tests is that as there are so many more tests there's no nice single page summary which shows the site's status. And selecting the individual tests is quite awkward in the way it's rendered in safari at any rate.
I will change my magic safari scotgrid status tab to show at least the SE and CE tests for the sites.
Edinburgh have been failing the replica management SFTs for over a week now. Initially, only one of the RM sub-tests (CE-sft-lcg-rm-rep) was failing, due to a server timeout problem (which I am sure was not a problem at our end since the dCache has been used almost continuously for the ongoing inter-T2 transfer tests). However, on Monday afternoon we started failing 4 of the sub-tests, and were getting an error that indicated a permissions problem with the /pnfs/epcc.ed.ac.uk/data/ops directory on our dCache (the SFTs are now running as ops). At the same time, the ops SAM tests started to fail with a similar error. Meantime, the dteam SAM tests were all green.
In order to try and work out what the problem was, I used /opt/edg/etc/grid-mapfile-local and mapped my DN to the ops VO. I could then use srmcp to copy files into and out of the ops directory of dCache. There were some problems in using the lcg-cr command, but it was unclear if this was to so with me trying to interact with the ops file catalog when my DN would map me to dteam. I also changed the dCache configuration to something more basic, just to check that this was not causing some problem, but this did not have an impact on the SFT results. Note, can be very tricky trying to debug a problem with a VO that you are not a member of.
However, about 2230 last night, the SFTs switched back to only failing on the single RM sub-test and at about 0100, the ops SAM tests started passing again. Strange, I know. Checking LCG-ROLLOUT this morning, there had already been a few postings about the RM tests failing with dCache's at other sites. It appeared that the cause of this was that Judit Novak (who helps run the SFTs) had now joined the ops VO, but her DN was still being mapped to dteam within the grid-mapfile. She has now unregistered from ops and has stopped (I think) the SFTs for today to ensure that the grid-mapfiles are up to date.
I'll update tomorrow if I see that things have changed.
In order to try and work out what the problem was, I used /opt/edg/etc/grid-mapfile-local and mapped my DN to the ops VO. I could then use srmcp to copy files into and out of the ops directory of dCache. There were some problems in using the lcg-cr command, but it was unclear if this was to so with me trying to interact with the ops file catalog when my DN would map me to dteam. I also changed the dCache configuration to something more basic, just to check that this was not causing some problem, but this did not have an impact on the SFT results. Note, can be very tricky trying to debug a problem with a VO that you are not a member of.
However, about 2230 last night, the SFTs switched back to only failing on the single RM sub-test and at about 0100, the ops SAM tests started passing again. Strange, I know. Checking LCG-ROLLOUT this morning, there had already been a few postings about the RM tests failing with dCache's at other sites. It appeared that the cause of this was that Judit Novak (who helps run the SFTs) had now joined the ops VO, but her DN was still being mapped to dteam within the grid-mapfile. She has now unregistered from ops and has stopped (I think) the SFTs for today to ensure that the grid-mapfiles are up to date.
I'll update tomorrow if I see that things have changed.
A little bit on last week's ClusterVision training. I've decided I quite like CVOS. It's a nicely constructed system for doing image management. Of course, I have not much to compare it to, (e.g. OSCAR, Rocks).
The trinity tool manages nodes' images, the DHCP server and named is basic, but easy to use.
A number of things, like power cycling nodes and running commands across the cluster are neatly sorted out (and one should never undervalue a simple thing which is done well).
However, it's clear that we're running into a lot of problems because CV moved wholesale to 64bit images and this does not work will when the OS has to be 32bit.
This is the problem we have - which requires the rather ugly patching in of a 64bit kernel to allow the image deployment to take place. In the end the installer was not converted back to 32bit. This isn't a disaster, of course, but demonstrates that some painting into a corner has happened...
I'll post my notes from the training session as a comment to this post.
The trinity tool manages nodes' images, the DHCP server and named is basic, but easy to use.
A number of things, like power cycling nodes and running commands across the cluster are neatly sorted out (and one should never undervalue a simple thing which is done well).
However, it's clear that we're running into a lot of problems because CV moved wholesale to 64bit images and this does not work will when the OS has to be 32bit.
This is the problem we have - which requires the rather ugly patching in of a 64bit kernel to allow the image deployment to take place. In the end the installer was not converted back to 32bit. This isn't a disaster, of course, but demonstrates that some painting into a corner has happened...
I'll post my notes from the training session as a comment to this post.
Monday, September 18, 2006
Friday, September 15, 2006
It's been a while since I regailed the world with our continuing ClusterVision saga, so grab a mug of tea, wrap a blanket around your shoulders and prepare for a meaty read...
I finally managed to speak to Alex on Monday 11th. We discussed some of the reasons why 32bit software might break when run in a 64 bit environment, which was technically interesting. However, the bottom line is that if software breaks on our site and runs fine everywhere else then it's us who look bad, even if it is the developers fault. So we really need a 32 bit installation. He said that is was possible for them to do this - it would require rebuilding the CVOS installer, after which building images would be easy. This would take until late Tuesday, so it was going to be Wednesday before we could get started.
The 32 bit image was duely delivered on Tuesday. It was nice to get something done on time. When I started working with it on Wednesday I found that it was reporting x86_64 via uname. I discovered that this was because it is a 32 bit OS, but running a 64 bit kernel. This means:
We had a meeting that Wednesday (13th), in addition to clarifying the above, the following was discussed:
I still felt that the division of responsibilities was very unclear - on the one hand CV were offering to do the base install for the worker nodes, leaving me to layer on the grid software, yet I was to do the grid nodes and disk servers.
On Thursday and Friday I customised the worker node image on node001. The basically consisted of:
After I had done this, I emailed Lowrens at ClusterVision to grab this image and patch in what RPMs CV wanted.
I finally managed to speak to Alex on Monday 11th. We discussed some of the reasons why 32bit software might break when run in a 64 bit environment, which was technically interesting. However, the bottom line is that if software breaks on our site and runs fine everywhere else then it's us who look bad, even if it is the developers fault. So we really need a 32 bit installation. He said that is was possible for them to do this - it would require rebuilding the CVOS installer, after which building images would be easy. This would take until late Tuesday, so it was going to be Wednesday before we could get started.
The 32 bit image was duely delivered on Tuesday. It was nice to get something done on time. When I started working with it on Wednesday I found that it was reporting x86_64 via uname. I discovered that this was because it is a 32 bit OS, but running a 64 bit kernel. This means:
- Applications which want to know their archictecture (like YUM) need to be run within a linux32 environment, which modifies the result of uname to i386. Otherwise YUM gets terribly confused, even when its configuration files have been namually set to the i386 repository.
- Therefore we probably need the job wrapper to execute in this environment, just to be on the safe side.
- Module loading is broken - only modules loaded within initrd are available. I consider this to be a security advantage.
- Memory handling is much better, because the kernel is 64 bit - it gets full bandwidth from the CPU to the memory and each running 32bit app can access 4GB.
We had a meeting that Wednesday (13th), in addition to clarifying the above, the following was discussed:
- The rest of the cluster will be delivered between 2 and 3 weeks.
- David and I were to get remote training in CVOS on Thursday.
- The SL307 worker node image on the master node has hostname lookup broken because resolv.conf is not correct.
- I would work on getting a base image for the gird servers (SL307 i386) and the disk servers (SL43 i386).
I still felt that the division of responsibilities was very unclear - on the one hand CV were offering to do the base install for the worker nodes, leaving me to layer on the grid software, yet I was to do the grid nodes and disk servers.
On Thursday and Friday I customised the worker node image on node001. The basically consisted of:
- Enabling YUM, pointed at a repository on the master node. Because of the x86_64 kernel issues I told YUM to leave the kernel well alone
- Patching in YAIM with a suitable site-info.defs.
- Manually adding Steve Traylen's torque packages for workers.
- Adding suitable ssh allowed keys.
- Enabling r* services (yes, we will run rsh inside the cluster)
After I had done this, I emailed Lowrens at ClusterVision to grab this image and patch in what RPMs CV wanted.
Thursday, September 07, 2006
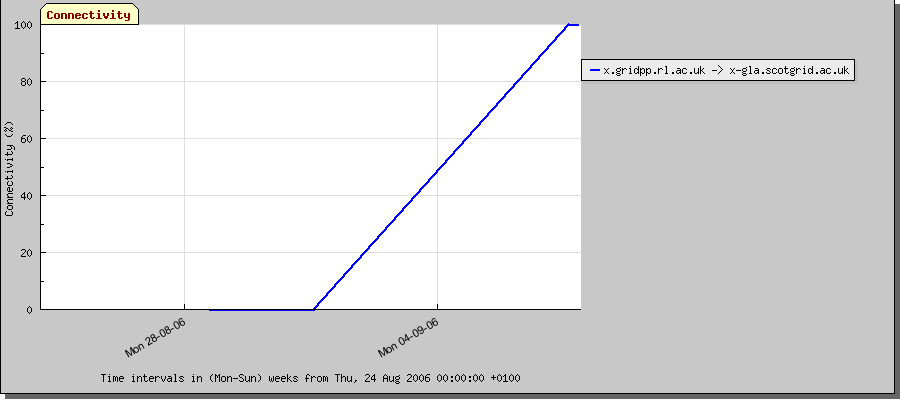
Finally got Glasgow's network monitor box opened up for ICMP connectivity probes. In the end it turned out to be a block on outgoing echo replies which was stopping the return packets from getting off campus.
Colin said this had been put in during the epidemics of windows RPC viruses which used ICMP echos to probe for new hosts.
That only took 3 months!
I finally got around to working on the YAIM support function for the new version of the DPM GIP plugin (the one which does the per-VO accounting by querying the database).
This turned out to be much easier that I had thought. I decided that I should not ask sites to set a password for the information user, so I introduced an optional DPM_INFO_PASS variable. If this isn't set then the system sets up a random password.
To support this I wrote a little utility python script that will generate a random string of ASCII alphanumerics. It does this by reading from /dev/random. Turns out that the 62 character "alphabet" of ASCII alphanumerics gives 5.95 bits of entropy per character - so 22 characters gives ~131 bits of entropy, so I made this the default.
I then wrote a new YAIM function, config_DPM_info, which sets sensible defaults for all the parameters it needs, adds permision to the DPNS database (using the MySQL root password) and writes the configuration file.
In the end I decided that if the function is re-run then it will reset the password for the dpminfo user - but in the case where no explicit password was set this seems ok.
I noticed that the DPM YAIM functions are a bit of mess now. They could really do with a spring clean - making each function perform a defintate single task, using the same coding style and decidng which variables are necessary and which optional. Importantly I see that the standard "dpmmgr" user is added to MySQL with full administrative privileges. This is definately a bug.
This turned out to be much easier that I had thought. I decided that I should not ask sites to set a password for the information user, so I introduced an optional DPM_INFO_PASS variable. If this isn't set then the system sets up a random password.
To support this I wrote a little utility python script that will generate a random string of ASCII alphanumerics. It does this by reading from /dev/random. Turns out that the 62 character "alphabet" of ASCII alphanumerics gives 5.95 bits of entropy per character - so 22 characters gives ~131 bits of entropy, so I made this the default.
I then wrote a new YAIM function, config_DPM_info, which sets sensible defaults for all the parameters it needs, adds permision to the DPNS database (using the MySQL root password) and writes the configuration file.
In the end I decided that if the function is re-run then it will reset the password for the dpminfo user - but in the case where no explicit password was set this seems ok.
I noticed that the DPM YAIM functions are a bit of mess now. They could really do with a spring clean - making each function perform a defintate single task, using the same coding style and decidng which variables are necessary and which optional. Importantly I see that the standard "dpmmgr" user is added to MySQL with full administrative privileges. This is definately a bug.
I'm getting increasingly annoyed at ClusterVision failing to deliver a cluster we can work with. The story so far is:
Hopefully we will make progress tomorrow, but if there's no sign of a working solution by Monday I'm going my own way with this.
- Monday: I have a chat with Louwrens on the phone - he sends some documentation on CVOS. I then have a poke around the masternode, with the aid of the documentation:
- CVOS seems quite simple - just a decently packaged set of scripts and utilities for setting up the fiddly bits on the cluster.
- rsync is used to grab and update images on running machines.
- Installation is done via a PXE boot, rsync then a pivot_root to swing onto the disk.
- In summary, it looks useful enough to have a go with. Especially for managing the worker nodes, which fit nicely into the cloned machine class (not so useful for the grid servers, though, but might be able to help us do backups).
- However, I find that they've given us x86_64 images. The experience of trying 32 bit DPM on x86_64 warns us against using this.
- I email Louwrens saying we need i386 builds. He emails back on Monday and we agree he will build these images for us.
- Tuesday: Alex phones. I'm at lunch and miss the call.
- Wednesday: I have an IM chat with Louwrens. He says that they had problems making i386 images. He says he'll get Alex to call me, but he doesn't.
- Thursday: I email Alex and Louwrens outlining our concerns - we've now wasted almost 4 working days since the cluster was installed and we've made no progress in setting it up.
- Thursday Afternoon: As I'm writing this I get an email from Louwrens saying that Alex did try and contact me today needing some questions answered. Did he try using skype as I asked? I had it on all day - no missed calls. I've asked at least for a summary of the issues via email.
Hopefully we will make progress tomorrow, but if there's no sign of a working solution by Monday I'm going my own way with this.
Tuesday, September 05, 2006
There's a temporry file handling bug in the grid/voms-proxy-init code, for which a patch has been released to gLite 3.0.
I had to purge the squid cache here at Glasgow to get it to look at glitesoft again, but after that apt did its magic.
Greig has done the Edinburgh dCache and UI. Steve's autoupdating mechanism should get the rest of Edinburgh tonight.
Durham currently don't have a working UI, so there's no great danger there, but hopefully Mark will push the upgrade through today or tomorrow.
I had to purge the squid cache here at Glasgow to get it to look at glitesoft again, but after that apt did its magic.
Greig has done the Edinburgh dCache and UI. Steve's autoupdating mechanism should get the rest of Edinburgh tonight.
Durham currently don't have a working UI, so there's no great danger there, but hopefully Mark will push the upgrade through today or tomorrow.
Monday, September 04, 2006
ClusterVision finished the installation of the first part of Glasgow's cluster on Friday. It has been lit up all weekend as burn in tests were run from Amsterdam. One worker node had a PSU explode and one of the grid nodes failed.
We should get the keys to the new cluster today - urgently we need to investigate image deployment via CVOS and get the site up and running as soon as we can.
It would be good to give Jamie a working DPM by the end of the week to help with the transfer tests, which seem to be having innumerable problems right now.
We should get the keys to the new cluster today - urgently we need to investigate image deployment via CVOS and get the site up and running as soon as we can.
It would be good to give Jamie a working DPM by the end of the week to help with the transfer tests, which seem to be having innumerable problems right now.
Durham died again on Saturday night when their CE went down. I suspect there's an issue with resource exhaustion and forking jobs here - Glasgow have suffered this in the past.
I'm encouraging Mark to set up ganglia ASAP so that at least we have some history to these events.
RRDTool on gstat is unfortunately useless in this case, because any rogue high value destroys the scale on the plots :-(
I'm encouraging Mark to set up ganglia ASAP so that at least we have some history to these events.
RRDTool on gstat is unfortunately useless in this case, because any rogue high value destroys the scale on the plots :-(
CERN haven't installed the new eScience certificate in the AFS shared certificate area.
See https://gus.fzk.de/pages/ticket_details.php?ticket=12151
See https://gus.fzk.de/pages/ticket_details.php?ticket=12151
Subscribe to:
Posts (Atom)