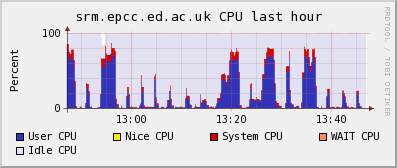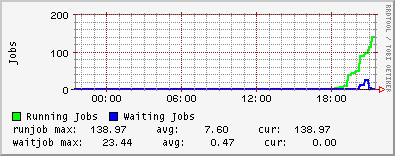
We were certified at 17:50 this evening. Immediately atlas jobs started coming in and running.
As of 23:00 we're running 152 jobs: 141 ATLAS, 11 Biomed.
The gstat plot shows us coming online really nicely!
ui1-gla:~$ edg-job-status --config rb/test.conf https://gm02.hep.ph.ic.ac.uk:9000/o6G2hiRip1t_smJPwk7QYA
******************************************************
BOOKKEEPING INFORMATION:
Status info for the Job : https://gm02.hep.ph.ic.ac.uk:9000 /o6G2hiRip1t_smJPwk7QYA
Current Status: Done (Success)
Exit code: 0
Status Reason: Job terminated successfully
Destination: svr016.gla.scotgrid.ac.uk:2119/ jobmanager-lcgpbs-dteam
reached on: Mon Oct 23 14:14:23 2006
******************************************************
ui1-gla:~$ edg-job-get-output https://gm02.hep.ph.ic.ac.uk:9000/ o6G2hiRip1t_smJPwk7QYA
Retrieving files from host: gm02.hep.ph.ic.ac.uk ( for
https://gm02.hep.ph.ic.ac.uk:9000/o6G2hiRip1t_smJPwk7QYA )
******************************************************
JOB GET OUTPUT OUTCOME
Output sandbox files for the job:
- https://gm02.hep.ph.ic.ac.uk:9000/o6G2hiRip1t_smJPwk7QYA
have been successfully retrieved and stored in the directory:
/tmp/jobOutput/graeme_o6G2hiRip1t_smJPwk7QYA
******************************************************
ui1-gla:~$ cat /tmp/jobOutput/graeme_o6G2hiRip1t_smJPwk7QYA/hw.out
Hello World