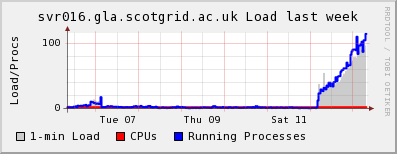
The cluster had its first weekend down - / filled up on the CE so that jobs could not start or end properly as sandboxes could not be gridftped. The information system also went belly up, as the plugins could not write their data. Some processes were clearly hanging as ganglia was reporting a load average of 100+ by this morning, so the node needed power cycled to come back to life.
Since then I have spent the most frustrating time clensing the batch system from all of the dead/zombified batch jobs. This was made worse by the fact that torque seemed to hang when it detected a job which had exceeded its wallclock time. It seemed to try and delete it on the worker node, but of course the job was long since gone, and it did not return. I wasted a lot of time thinking it was maui which was hanging - as maui does hang if torque is not responding properly.
By the time I realised all of this I had rebooted several times and even put the site into downtime in an attempt to purge things.
There seems to be no good way to clear up this mess. Manually checking a few of the jobs which were in state 0 cpu used but running, it was clear they were no longer on the worker nodes, but there seemed to be no good way to automatically probe this status. In the end I had to pick all the old jobs (id < 26800) which were showing 0 cpu time used, and were in state "R", and force their deletion with "qdel -p".
Finally, there were a number of jobs in state "W" which must have come in this morning when things were flaky, which could not be started properly so they had to be qdeled too (see last week's post).
As remedial action, I have moved /var onto the large disk partition and made a soft link in /. Compression of logfiles has been enabled, and at the next downtime /home will also be moved.
No comments:
Post a Comment