We have finally killed off our DPM at Edinburgh! The machine has been reinstalled with SL4.3 and once the DNS has been changed to reflect the new hostname we will configure it as a second dCache pool node. In parallel with the reinstall we reconfigured the site so use our dCache as the default SE. According to gstat, so far, so good but we are still waiting for the first SFT to run.
The new dCache pool node will be connected to about 12TB of disk and since it will run a GridFTP door, we should be able to sustain higher bandwidths into the site than are currently possible. Now need to look at running xfs on the disk pools which we know will give additional gains in performance. Initial tests on a test node have shown the problems with xfs on SL4 to have been solved if the latest (2.6.9-34.0.2) kernel is used.
Next on the dCache todo list is finding a suitable way to utilise the SAN storage across NFS. Using it as a disk based HSM is a possibility but then no one has done this before....
Thursday, August 31, 2006

Monday, August 28, 2006
Glasgow goes down in a cloud of smoke...
Electrical engineers preparing for the new cluster's arrival tomorrow touched one of the bus bars under the floor this afternoon. It promptly exploded in a cloud of oxidised copper. It seems that the plastic housing around the bus bar had become hot and had started to carbonise, shorting the circuit.
They have hacksawed off 20cm from the bus bar to shorten it away from the affected area.
Unfortunately they also managed to damage one of the circuit switches in the main distribution board. This means the 200A supply to the room is down until tomorrow. In addition the repair, tomorrow, to the old breaker (and it is old) is temporary - it will have to be taken down properly and replaced at a later date. More downtime.
In the meantime I managed to move all of the remaining bits of scotgrid-gla onto the unaffected wall sockets and limp back up (lost all the jobs, of course). All the WNs came up without the DHCP server being alive, so they all needed rebooted to pick up their IP addresses. Also discovered that the NAT box (grid01) did not have IP forwarding enabled by default - yet another fiddly bit it's hard to test.
Unfortunately, after coming home, I realised that ssh on the CE didn't come back up properly (the current cluster arrangements are somewhat ad hoc, at best). So we're down until I can fix that tomorrow morning.
Electrical engineers preparing for the new cluster's arrival tomorrow touched one of the bus bars under the floor this afternoon. It promptly exploded in a cloud of oxidised copper. It seems that the plastic housing around the bus bar had become hot and had started to carbonise, shorting the circuit.
They have hacksawed off 20cm from the bus bar to shorten it away from the affected area.
Unfortunately they also managed to damage one of the circuit switches in the main distribution board. This means the 200A supply to the room is down until tomorrow. In addition the repair, tomorrow, to the old breaker (and it is old) is temporary - it will have to be taken down properly and replaced at a later date. More downtime.
In the meantime I managed to move all of the remaining bits of scotgrid-gla onto the unaffected wall sockets and limp back up (lost all the jobs, of course). All the WNs came up without the DHCP server being alive, so they all needed rebooted to pick up their IP addresses. Also discovered that the NAT box (grid01) did not have IP forwarding enabled by default - yet another fiddly bit it's hard to test.
Unfortunately, after coming home, I realised that ssh on the CE didn't come back up properly (the current cluster arrangements are somewhat ad hoc, at best). So we're down until I can fix that tomorrow morning.
Edinburgh got a ticket for a single lcg-rm failure. Meanwhile Durham has been down for almost 72 hours (no ticket), Glasgow has been down for ~6 hours after our power/networking failure. Neither of these sites have been given tickets.
Go figure...
Go figure...
DPM on SL4.
I tested DPM on SL4 last week. The i386 version worked fine. This is good from the point of view of hardware support in the kernel, however it does not help with support for xfs, which is still our preferred filesystem.
The x86_64 version turned out to be very hard to install - some bug in anaconda was causing all of the device nodes in /dev to dissapear shortly after formatting disk partitions. I couldn't find anything on google at all about this, but it's such a critical bug I find it amazing that no one else has experienced it. Must join the sl-users mailing list and report this.
Found a work around: first time around create the partitions - this install will then fail with the /dev/null bug above; then restart, but create no partitions, which works around the bug. What a pain! It means that our kickstart auto-installation of SL4 x86_64 nodes does not work.
In order to install the i386 packages needed by the gLite middleware I found yum to be far superior to apt - yum was able to look at the whole repository and pull the necessary i386 compatibility packages, where as apt seemed completely stymied.
Testing DPM, finally, on this platform seems to have revealed a bug in the dpm daemon itself. It seems to be unable to authenticate users, even when they are listed in the cns_db/userinfo table. This is even weirder, because dpns (e.g., dpns-ls) works fine. rfio and dpm-gsiftp both also work fine. If this turns out to be a real problem then at least the disk pools, which are the important component, can be run on SL4, with the headnode on SL3.
I will reboot today and we'll see if that helps - there were some issues with the database and hostnames (again).
See http://www.gridpp.ac.uk/wiki/Installing_SL3_build_of_DPM_on_SL4.
I tested DPM on SL4 last week. The i386 version worked fine. This is good from the point of view of hardware support in the kernel, however it does not help with support for xfs, which is still our preferred filesystem.
The x86_64 version turned out to be very hard to install - some bug in anaconda was causing all of the device nodes in /dev to dissapear shortly after formatting disk partitions. I couldn't find anything on google at all about this, but it's such a critical bug I find it amazing that no one else has experienced it. Must join the sl-users mailing list and report this.
Found a work around: first time around create the partitions - this install will then fail with the /dev/null bug above; then restart, but create no partitions, which works around the bug. What a pain! It means that our kickstart auto-installation of SL4 x86_64 nodes does not work.
In order to install the i386 packages needed by the gLite middleware I found yum to be far superior to apt - yum was able to look at the whole repository and pull the necessary i386 compatibility packages, where as apt seemed completely stymied.
Testing DPM, finally, on this platform seems to have revealed a bug in the dpm daemon itself. It seems to be unable to authenticate users, even when they are listed in the cns_db/userinfo table. This is even weirder, because dpns (e.g., dpns-ls) works fine. rfio and dpm-gsiftp both also work fine. If this turns out to be a real problem then at least the disk pools, which are the important component, can be run on SL4, with the headnode on SL3.
I will reboot today and we'll see if that helps - there were some issues with the database and hostnames (again).
See http://www.gridpp.ac.uk/wiki/Installing_SL3_build_of_DPM_on_SL4.
Glasgow's new cluster is supposed to arrive tomorrow. The schedule is:
There are a number of outstanding problems to be resolved. On the prosaic side we need to know what size of lorry the cluster will be delivered in and which entrance they will use. These things are still unclear!
More seriously, no definite statement has been made about how we support SL3 nodes on the new cluster. I will continue to work on a systemimager solution as a fallback position.
- Tuesday 29th: Cluster delivery
- Wednesday 30th - Friday 1st: Installation on site by ClusterVision Engineers
- Monday 4th: Training for David and Graeme in management (power switching, CVOS, IPMI, networking, etc.)
There are a number of outstanding problems to be resolved. On the prosaic side we need to know what size of lorry the cluster will be delivered in and which entrance they will use. These things are still unclear!
More seriously, no definite statement has been made about how we support SL3 nodes on the new cluster. I will continue to work on a systemimager solution as a fallback position.
Durham went down over the weekend. Looks like their CE failed about midnight on Friday - JS started to fail from Saturday 1am.
Of course this is compounded by Monday being a bank holiday, so I don't expect Mark to be able to sort this until Tuesday. This brings up an interesting question for T2s - the 72 hour response time is fine over a normal weekend, but apply any extended holidays and it's not going to be fulfilled.
Even if we do get distributed support sorted out this is not going to be easy to satisfy over Christmas and New Year holidays, when no one will want to be about.
I can't see Universities paying overtime for this!
Of course this is compounded by Monday being a bank holiday, so I don't expect Mark to be able to sort this until Tuesday. This brings up an interesting question for T2s - the 72 hour response time is fine over a normal weekend, but apply any extended holidays and it's not going to be fulfilled.
Even if we do get distributed support sorted out this is not going to be easy to satisfy over Christmas and New Year holidays, when no one will want to be about.
I can't see Universities paying overtime for this!
Tuesday, August 22, 2006
gLite upgrade this morning: 3.0.1 to 3.0.2.
Glasgow got bitten by the bug in lcg-info-dynamic-scheduler:
https://gus.fzk.de/pages/ticket_details.php?ticket=11578
This was a very minor upgrade though - the only new service was a BDII upgrade on the CE.
Glasgow got bitten by the bug in lcg-info-dynamic-scheduler:
https://gus.fzk.de/pages/ticket_details.php?ticket=11578
This was a very minor upgrade though - the only new service was a BDII upgrade on the CE.
Friday, August 18, 2006
Mon box weirdness: we started to fail APEL, RGMA and RGMASC SFTs last night. I started trying to restart services and found they were all failing because of a java sdk update (from 1.4.2_08 to 1.4.2_12).
This is bizarre because this update happened ages ago. Why start failing now?
I also had to update the JAVA_HOME in no less than 5 locations:
Now how stupid is that?
This is bizarre because this update happened ages ago. Why start failing now?
I also had to update the JAVA_HOME in no less than 5 locations:
/etc/java.conf
/etc/java/java.conf
/etc/tomcat5/tomcat5.conf
/opt/edg/etc/profile.d/j2.sh
/opt/edg/etc/profile.d/j2.csh
Now how stupid is that?
Friday, August 11, 2006
After being suspicious for some time that the CMS jobs we were taking were not actually completing, successfully, but instead just running out of CPU time I finally got around to having a look at the accounting logs on PBS. This seemed to bear out my fears: the exit status of the jobs was always 271, with a CPU usage some tens of seconds over the 48:00 limit (which had been set by YAIM when it set up the queues).
I wonder why we never got a ticket? We have processed hundreds of these jobs and I suppose that all of them have failed and been wasted.
I have now doubled the maximum CPU time to 96 hours, and bumped the wall time to 144 hours. After this weekend we'll see if that was enough.
PS. The documentation for torque's qmgr is terrible - I had to almost guess the resource name for CPU time. Yuk!
I wonder why we never got a ticket? We have processed hundreds of these jobs and I suppose that all of them have failed and been wasted.
I have now doubled the maximum CPU time to 96 hours, and bumped the wall time to 144 hours. After this weekend we'll see if that was enough.
PS. The documentation for torque's qmgr is terrible - I had to almost guess the resource name for CPU time. Yuk!
Edinburgh finally got pushed over the edge by the LHCb jobs - the CE became unstable and the BDII failed.
The GGUS ticket is https://gus.fzk.de/pages/ticket_details.php?ticket=11192&from=allt.
There's no evidence that Edinburgh ever published an annomolously low ERT which would have sucked these jobs in, so I think it must have been an LHCb problem:


The GGUS ticket is https://gus.fzk.de/pages/ticket_details.php?ticket=11192&from=allt.
There's no evidence that Edinburgh ever published an annomolously low ERT which would have sucked these jobs in, so I think it must have been an LHCb problem:
Wednesday, August 09, 2006
The issue of what we get on the new ClusterVision cluster is to be discussed today.
I think that SL3 on the grid frontends and the WNs is necessary, but I worry that there might be some nasty driver issue lurking. I'm not sure they've tested SL3 properly.
The nodes which I want to run SL4 on, from the start, are the disk servers. Here we'd like to use xfs for the underlying filesystem, which is safe in 64bits, but dodgy in 32bit x86. It will also spare us the headache of data migration/preservation when the grid middleware finally makes its triumphant leap to SL4.
There are some posts on LCG-ROLLOUT indicating this is possible to so - just need to patch in some of the SL3 RPMs which the 32 bit version of the DPM disk server needs.
Obviously this has to be tested before the machines arrive on the ground - anyone got a time machine?
I think that SL3 on the grid frontends and the WNs is necessary, but I worry that there might be some nasty driver issue lurking. I'm not sure they've tested SL3 properly.
The nodes which I want to run SL4 on, from the start, are the disk servers. Here we'd like to use xfs for the underlying filesystem, which is safe in 64bits, but dodgy in 32bit x86. It will also spare us the headache of data migration/preservation when the grid middleware finally makes its triumphant leap to SL4.
There are some posts on LCG-ROLLOUT indicating this is possible to so - just need to patch in some of the SL3 RPMs which the 32 bit version of the DPM disk server needs.
Obviously this has to be tested before the machines arrive on the ground - anyone got a time machine?
Tuesday, August 08, 2006
VO Software
We got a ticket from LHCb about a missing RPM on our reinstalled cluster.
It's long been my opinion that this needs to be addressed by having VO specific meta-packages: lcg-lhcb RPMs with all of their dependencies. Otherwise it's almost impossible to find out what a VO needs. A manual list on the CIC portal would be a step forward, but it's too much to do this by hand for multiple VOs.
It's long been my opinion that this needs to be addressed by having VO specific meta-packages: lcg-lhcb RPMs with all of their dependencies. Otherwise it's almost impossible to find out what a VO needs. A manual list on the CIC portal would be a step forward, but it's too much to do this by hand for multiple VOs.
Friday, August 04, 2006
First entry for the ScotGrid blog.
Edinburgh failing RGMA and APEL for a few days. Possibly their mon box has gone crazy.
Have been investigating icmp firewalling issues to the gridpp network
monitoring box at Glasgow. The network people say we have this open, but the packets just don't get through. Will follow up on Monday.
Glasgow continue to have unresolved delivery problems on the new
cluster. Latest estimate is arrival ~2006-08-21. We have a phone meeting with clustervision on Monday.
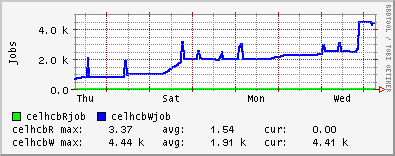
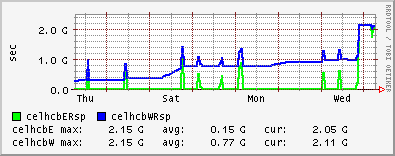
Edinburgh had 100s of jobs submitted to their site from a single LHCb
user, giving them a queue of 500+ (with 7 WNs!). This queue has now
risen to 1139! See
http://goc.grid.sinica.edu.tw/gstat/ScotGRID-Edinburgh/celhcb_job_.html
Looks like a GGUS ticket heading some user's way...
Edinburgh failing RGMA and APEL for a few days. Possibly their mon box has gone crazy.
Have been investigating icmp firewalling issues to the gridpp network
monitoring box at Glasgow. The network people say we have this open, but the packets just don't get through. Will follow up on Monday.
Glasgow continue to have unresolved delivery problems on the new
cluster. Latest estimate is arrival ~2006-08-21. We have a phone meeting with clustervision on Monday.
Edinburgh had 100s of jobs submitted to their site from a single LHCb
user, giving them a queue of 500+ (with 7 WNs!). This queue has now
risen to 1139! See
http://goc.grid.sinica.edu.tw/gstat/ScotGRID-Edinburgh/celhcb_job_.html
Looks like a GGUS ticket heading some user's way...
Subscribe to:
Posts (Atom)