We got alerted by our users to that fact that svr020 was going very, very slowly. When I logged in it took more than a minute and a simple ls on one of the nfs areas was taking ~20s.
Naturally these damn things always happen when you're away and sitting with a 15% battery in a session which is actually of interest!
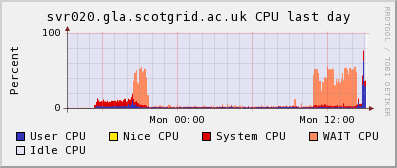
Anyway, I couldn't see what was wrong on svr020 - the sluggishness seemed symptomatic rather than tied to any bad process or user. There were clear periods when we hit serious CPU Wait. When I checked on disk037 I found many, many error messages like:
nfsd: too many open TCP sockets, consider increasing the number of nfsd threadsnfsd: last TCP connect from 10.141.0.101:816When I checked on the worker nodes, sure enough, we seemed to have inadvertently switched to using tcp for nfs - I later found out this is the default mount option on 2.6 kernels (which we've obviously just switched to).
I decided to follow the advice in the error message, and run more nfsd threads, so I created a file /etc/sysconfig/nfs, with RPCNFSDCOUNT=24 (the default is 8). I then (rather nervously) restarted nfs on disk037.

Having done this, the load on svr020 returned to normal and the kernel error messages stopped on disk037. Whew!
Relief could clearly be seen, with the cluster load dropping back down to the number of running processes, instead of being "overloaded" as it had been.
We should use MonAMI to monitor the number of nfs tcp connections on disk037. (Just out of interest the number now is 343, which must have caused problems for 8 nfs server daemons; hence, 24 should scale to ~900 mounts.)
Of course, we could shift back to udp nfs mounts if we wanted. Reading through the
NFS FAQ might help us decide.

