CLOSE_WAIT strikes again!
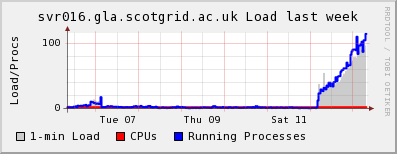
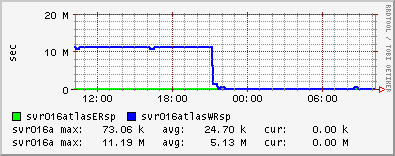
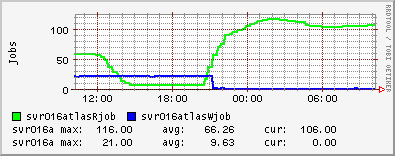
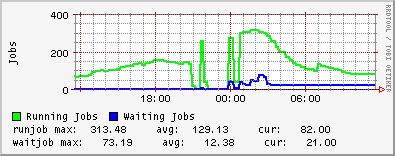
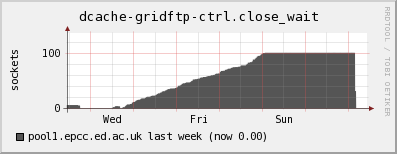
Since Wednesday, the number of tcp connections on one of our dCache door nodes that remain in a CLOSE_WAIT state have been steadily increasing. Once the number of CLOSE_WAITs reached the MaxLogin value (100) for the door, there was no further increase. For information, I upgraded to the v1.7.0-19 of dcache-server on Wednesday. UKI-NORTHGRID-LANCS-HEP are also experiencing the
CLOSE_WAIT problem.
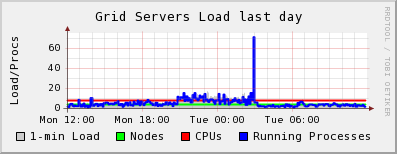
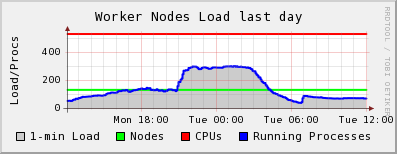
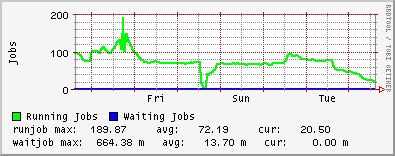
I should also add that ~0409 this morning all of the dCache processes on one of my door nodes and the head node died simultaneously. You can see the sharp drop in CLOSE_WAITs in the ganglia plot as the door process stopped. Initially I thought this was connected to the CLOSE_WAIT issue, but deeper investigation showed that dcache-server v1.7.0-20 was released yesterday which was automatically updated on my nodes and subsequently caused the running services to stop working. I know that it must have been the update since the dCache services continued to run on the one node which did not have automatic updates enabled.
The log files contained references to runIO errors before stopping.
11/21 04:06:08 Cell(c-100@gridftp-pool1Domain) : runIO :
java.lang.InterruptedException: runIo has been interrupted
11/21 04:06:08 Cell(c-100@gridftp-pool1Domain) : connectionThread
interrupted
Automatic updates of dCache have been turned off. It is always the case that after upgrade you must re-run the YAIM configure_node function or run the dCache install.sh script. Otherwise tomcat will not start up due to a problem with the definition of the JAVA_HOME variable (even if it has not changed during the update).
So, in summary:
1. The CLOSE_WAIT issue is very much alive and kicking in v1.7.0 of dCache.
2. It is highly recommended to update your dCache by hand to make sure that everything comes back up.